| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
VSP crash (not solved yet)
I recently found my C64C to be very prone to crash with certain demos and finally managed to create a reproducible crash while banging the $d011 register so I hooked up my logic analyzer and here are some logs of the event taking place.
http://oms.wmhost.com/misc/VSP_Crash_100MHz.zip
A testprogram was looped at address $0ff0. It could've been placed at pretty much any $xxf0 address and it still would crash within few seconds. Running the code at lower offset on the memorypage quite effectively prevented it from crashing on the machine used for testing. A shorter version with only inc/dec/inc/jmp not crossing the page boundary crashes.
The symptoms were always the same; low address byte of the 2nd inc at $xxf7 and/or the opcode of the jmp at $xxff are suddenly trashed. The byte at $xxf7 ends up being 0x00, 0x01, 0x10 or 0x1d. Byte at $xxff ends up being 0x0c, 0x40, 0x48 or 0x4d.
As a post-work the decoupling caps of the memorychips in the C64C used were replaced and a new thick wire delivering power directly to the memorychips was soldered in place. This had no effect and the machine still crashes with this code, as well as with Booze Design demos Royal Arte and Tsunami for example. Powersupply used is a C128 PSU with C64 powercable soldered next to the C128 powercable.
Logfiles VSP Crash 100MHz 3_31.csv/txt have the actual crash event taking place.
|
|
| |
Skate
Registered: Jul 2003
Posts: 491 |
That's an interesting subject. What is the main purpose? Is it making a hardware patch? Or creating a test program which can detect problems and prepare the VSP routine according to that machine's bug? I think second one would be awesome but I have a doubt if it is possible or not. |
| |
iAN CooG
Registered: May 2002
Posts: 3136 |
If anything, buggy VSPs could be patched knowing that you shouldn't fiddle with d011 at addresses $xxFx by relocating code
Zerox #1 |
| |
Skate
Registered: Jul 2003
Posts: 491 |
@iAN CooG: yes, but is it always the same addresses in different problematic machines? that's the real question i guess. |
| |
Krill
Registered: Apr 2002
Posts: 2850 |
I just checked two programs which came off the top of my head when i thought of VSP crash-prone: The side-scrolling levels in the classic game Creatures and the two-VSP bitmap scroller on the 2nd side of Xenon's Arcanum.
Creatures has the two VSP write accesses to $d011 at $23b1, and the Arcanum part has them at $2750 and $2d51.
Apparently it's not only $xxfx which is prone to crashes, but maybe there is some kind of logic, as Skate suggested.
Maybe it's a question of how many bits are set in certain ranges of the opcode's address, such that e.g. in zero-page would be quite safe and at $fffx the opposite, while the crash probability distribution in between them is somewhat different from machine to machine, similar to SID filter curves.
But maybe there are also more variables in the equation than just the opcode's address and the particular machine.
I congratulate ZeroX for this discovery though, it's another stepping stone on solving one of the last mysteries of the C-64. :) |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1380 |
Intriguing. I have in the past had C64Cs that were very prone to crashing, one to the extent that I nearly despaired of my $d011 scroller being suitable for commercial use. I didn't consider the possibility of it being code-location dependent. If I still had that machine I'd do some tests.. |
| |
S.E.S.
Registered: Apr 2010
Posts: 19 |
It would be very cool to know the real cause for the crashes. Is it VIC and it's RAM refresh counter running wild? IMHO the ultimate goal is to be able to emulate those crashes in an emulator.
From a coder's point of view, I'd be very glad to know how to avoid those crashes. When creating a new demo part, I always hesitate to use heavy VSP magic because I don't want to leave out too many viewers with real hardware. It would be so cool if there would be some rule of thumb, for example your VSP is safe as long as all writes are from adresses in ranges $xx00 - $xx3F. |
| |
algorithm
Registered: May 2002
Posts: 702 |
Very interesting. If this issue with VSP can somewhat be solved it would be great. Zero-X, you had mentioned that placing the code at lower offset stopped the crashes on your machine. Like krill mentioned, it may vary from machine to machine as there does not seem to be any VSP routine in any demo that never crashes. If there is any such demo which uses AGSP/VSP/Linecrunch that does not crash, this would be what to target and analyse |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
One of the problem is likely that same code doesn't crash on all crash prone machines. So far I only know this piece of code crashes also Jope's machine right away repeatedly.
Maybe the same code crashes on different memory location on other machines. Maybe another kind of code is required. Who knows.
All I've been able to spot from the logic dumps so far is what seems as at some point VIC pulls the BA line low after the first INC, CPU stops after processing the first DEC opcode three times (is that correct behaviour, just fetching the opcode 3x without the address bytes?), after VIC releases the BA line CPU continues executing the loop, but when it fetches the second INC from the memory the low address byte has been trashed, and when it gets to fetch the JMP, also that opcode has been trashed and BOOM.
Btw I noticed from the included gif and dump that I might've left the AEC probe disconnected as it's seen always as high. In my other dumps it's behaving as it should.
|
| |
encore
Registered: Aug 2010
Posts: 61 |
How about asking Bil Herd? After seeing a couple of his videos, I could imagine that he would have an idea or two.
http://c128.com/forums/general-discussion |
| |
AmiDog
Registered: Mar 2003
Posts: 97 |
Has anyone tried running a problematic C64 using batteries or some kind of filtered PSU? Or even on 5V only (if possible, can't remember which parts require 9V to work)? After reading about the various issues Jens of Individual Computers faced with his ACA1230 accelerator due to noisy PSUs, it would be a good idea to ensure it's not related to the PSU in any way... |
| |
Skate
Registered: Jul 2003
Posts: 491 |
@AmiDog: I'd had two c64s but only one PSU back in the days. One of them had VSP problems but other one was completely fine. Maybe other one had the same problem but with different memory addresses (like discussed above), I'm not sure. But same PSU worked fine with one of the machines. I'm sure many c64 users have experienced the same thing. Just my 2 cents. |
| |
WVL
Registered: Mar 2002
Posts: 886 |
Quote: I just checked two programs which came off the top of my head when i thought of VSP crash-prone: The side-scrolling levels in the classic game Creatures and the two-VSP bitmap scroller on the 2nd side of Xenon's Arcanum.
Creatures has the two VSP write accesses to $d011 at $23b1, and the Arcanum part has them at $2750 and $2d51.
Apparently it's not only $xxfx which is prone to crashes, but maybe there is some kind of logic, as Skate suggested.
Maybe it's a question of how many bits are set in certain ranges of the opcode's address, such that e.g. in zero-page would be quite safe and at $fffx the opposite, while the crash probability distribution in between them is somewhat different from machine to machine, similar to SID filter curves.
But maybe there are also more variables in the equation than just the opcode's address and the particular machine.
I congratulate ZeroX for this discovery though, it's another stepping stone on solving one of the last mysteries of the C-64. :)
I think that mostly has to do with there being 3 VSP's in that part with the scrollers. One VSP to scroll the top part, another to stabilize the screen again and a third to scroll the bottom.
If you disable one of the VSP's (or two), then suddenly it doesnt crash that often anymore. I think it's still a totally weird phenomenon.
Changing VIC's, memory and PSU did not help anything at all during my tests.
The pattern is always the same, the code crashes because memory gets destroyed. You will see destroyed bits in different at the same offset yy (differing all the times) at a lot banks xx $xxyy.
An idea I had was to write some test code in a ROM, so the code would _never_ mess up! That way you could analyse a lot better what happens to the RAM, by simply looking at the screen (bitmap mode or something) to see what gets destroyed and when it gets destroyed.
I think nowadays it would be pretty easy to write a small 8KB testprogram for a cartridge and emulate that cart in 1541u or easyflash or something :) |
| |
enigma
Registered: Feb 2002
Posts: 14 |
That code from ROM idea is quite nice, you may find some pattern in the memory corruption.
On the other hand the first step would be to find out where the incorrect write to RAM appears.
So either a regular write to RAM is seen with a wrong address or it has something to do with refresh.
So with the logic analyzers logs it should be possible to find a RAM read that delivers a wrong value. Even if the CPU does not crash you can compare to a table of expected RAM values.
From this point one could go backward and find f.e. the last refresh to this page and take a look at the time difference (which should not exceed 3.66 ms I think).
I am not sure if the logic analyzer can detect if some signal timing gets corrupted, such as that a signal is not active for 500 ms but just 10 ms f.e.
If it is a regular RAM write the next step would be to identify the source.
Another cause might be that the switching between CPU and VIC as bus master collides if one chip shifts timing by a few ms. Sounds unlikely but as this crash appears just on some C64s and is more or less random gives the whole thing a kind of analog touch...
|
| |
Flavioweb
Registered: Nov 2011
Posts: 447 |
have you considerated some radio frequency interferences?
I remember that an old etacs standard cell phone caused many crash problems to me in the past...
Just try to turn off all phones and other rf sources (wireless routers, headphones, and so on)... |
| |
S.E.S.
Registered: Apr 2010
Posts: 19 |
@WVL: That sounds promising! I really wish someone would investigate further on this topic. He has to get his hands on a VSP-crashing C64, though. |
| |
algorithm
Registered: May 2002
Posts: 702 |
I had stated this it many posts previously, but when i actually had a real c64, changing the power supply to a new one removed all crashes completely. I know this may differ from c64 to c64, but just a note |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
I now have two working C64C setups, identical board revisions, running from the same C128 PSU. I'm using the same VIC-II and 8701 clock generator on both of them. One machine keeps crashing, the other one does not. I should try socketing each and every chip on both boards and then do so swapping around to see if that would give any better results.
|
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Some more testing...
Jope checked his C64C that crashes with this inc/dec $d011 loop and it had the same motherboard revision 250469 with the same gluelogic MOS 251715-01 and same NEC memorychips, tho different speed.
I also repaired one of the C128s from my junkpile and it also seems to be very touchy with that bit of code, trashing the same $xxf7/ff bytes, BUT I can't get it to crash with any of the demos...
|
| |
Graham
Account closed
Registered: Dec 2002
Posts: 990 |
Quoting ChristopherJamIntriguing. I have in the past had C64Cs that were very prone to crashing, one to the extent that I nearly despaired of my $d011 scroller being suitable for commercial use.
I think I never released any VSP/AGSP stuff because of that. On my machine you had to power-cycle it about 30 times until you reached "that weirdo stable non-crashing state" so you could actually code VSP/AGSP. But I wanted stuff which always works. |
| |
Skate
Registered: Jul 2003
Posts: 491 |
Actually, development is much easier now thanks to reliable emulators since they don't have VSP crashing bugs (even if they should).
VSP is like the cancer of C64. No existing cure but not always kills. We may try different PSUs, and some hardware modifications and call it "chemotherapy". :) |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Continuing from Controlling that colour change bug thing
<some_time_later>
Of the available caps I had I've successfully tried 2.2nF cap and then 4.7nF which again renders the C64C unable to start up.
For the couple of demos I've tried so far:
Royal Arte:
The scrolling logo used to crash in couple of seconds. It still crashes now, but takes several minutes.
Dutch Breeze:
Couldn't get past the diagonally scrolling Dutch Breeze -logo. Now haven't been able to crash it so far.
Tequila Sunrise:
Previously it was luck to get it even to start/show something on screen. Again, now no crashes/glitches detected so far.
The little inc/dec/inc/dec/inc-loop I've been using to crash the machines still crashes, but that too now takes a while before it happens.
So delaying the VIC Chip Select -signal could be a step into the right direction.
|
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Yesterday added some more caps to delay few other signals in the testing machine and the most crashing Tequila Sunrise has now been running for around 18 hours without any sign of corruption.
On the other hand, Royal Arte is still almost as crashing as it was before.
My own code at the moment seems to crash only when the memory has been filled certain way. Fill it with some steady value and the code keeps running just fine.
|
| |
Frantic
Registered: Mar 2003
Posts: 1627 |
This thread is like a thriller! I love it. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Spent couple of hours chatting and looking at logic analyzer logs with Jens at Revision. That was fun.
At the moment all the delay-caps have been removed, so the grey dots are back, and another tiny fix is being testdriven.
My $d011 inc/dec-code, couple of test routines, Tequila Sunrise, Tsunami, Dutch Breeze, IK+VSP, perhaps some others I forgot, and Royal Arte... None are glitching or crashing.
Now running some 18 hour Royal Arte -marathon to see if I could still get it to crash.
[ ] Achievement unlocked... |
| |
WVL
Registered: Mar 2002
Posts: 886 |
I should have a standalone version of those double scrollers from Arcanum somewhere, so you can run it endlessly. Will have a look for it, might make a nice test program. |
| |
Skate
Registered: Jul 2003
Posts: 491 |
@Zer0-X: Great work pal. What if we try your hw patch with a working c64? Would it still run or start crashing? I mean if you find a certain way to stop VSP crashes, will we be able to patch all c64s the same way without even testing them if they already crash or not? |
| |
Zyron
Registered: Jan 2002
Posts: 2381 |
Just showing my enthusiasm. This thread is very interesting. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Royal Arte has been running for the past 16 hours now and still no visible glitches. Previously that demo (or rather the Royal Arte logopart) would've worked for 10 minutes at best.
And the fix is of such generic type that it can be made into C64, C64C and C128 all with minimum effort. Should any side-effect whatsoever to be observed, removing it will be just as easy. Ofcourse then we would have to find yet another way to fix the bug.
WVL: Wish I had more powersupplies to test more than one machine at a time. Tho if you can work on some of your old sources I can give it a testdrive.
Now to test this on my other C64C, which is less crashy, and one of the C128s that trashes whole lot of memory when the crash happens. |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
Quote: Royal Arte has been running for the past 16 hours now and still no visible glitches. Previously that demo (or rather the Royal Arte logopart) would've worked for 10 minutes at best.
And the fix is of such generic type that it can be made into C64, C64C and C128 all with minimum effort. Should any side-effect whatsoever to be observed, removing it will be just as easy. Ofcourse then we would have to find yet another way to fix the bug.
WVL: Wish I had more powersupplies to test more than one machine at a time. Tho if you can work on some of your old sources I can give it a testdrive.
Now to test this on my other C64C, which is less crashy, and one of the C128s that trashes whole lot of memory when the crash happens.
What is the current fix you're using? (You said you removed the caps). |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Better not spread too much false information.
Yesterday I "fixed" another C64C and had two machine that wouldn't crash. Then cleaned up some solderwork and I now have two machines that crash just as they did before. Have to spend some time with those during the weekend and figure out what went wrong.
At first it was so promising... and then it VSP'd. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Current situation:
- Royal Arte works just fine.
- Dutch Breeze works just fine.
- Tequila Sunrise crashes after a few minutes.
On the C64C:
- Separate cable delivering 5V for the DRAMs.
- Separate cable connecting grounds between VIC and DRAMs.
- Tripled the capacitance of the DRAM decoupling caps.
- Added terminating resistor on RAS.
- Added pull-up resistor on RAS.
Previously the ripple on the DRAM powerlines was around ~600mV, now ~250mV. NEC datasheets say to ensure proper operation of their DRAMs the ripple needs to be kept below 500mV.
Before pull-up RAS was only climbing up to around 3.5V, now it gets all the way to 5V.
But as Tequila Sunrise still crashes something doesn't add up...
|
| |
lft
Registered: Jul 2007
Posts: 369 |
After staring at those logs for an unhealthy amount of time, I think I see it.
Here's the relevant part of "VSP Crash 100MHz 3_31.txt". We enter at the end of
the CPU halfcycle where $41 was written to d011 to enable the badline condition
in the middle of a line.
Time Addr Data R/W RAS CAS BA PH0
-60.01us | 0XD0 | 0X41 0 0 1 1 1
-60us | 0XD0 | 0X41 0 0 1 1 1
-59.99us | 0XD0 | 0X41 0 0 1 1 1
-59.98us | 0XD0 | 0X41 0 0 1 1 0 VIC halfcycle begins.
-59.97us | 0XD0 | 0X41 0 0 1 1 0
-59.96us | 0XD0 | 0X41 1 1 1 1 0
-59.95us | 0XD0 | 0X41 1 1 1 1 0
-59.94us | 0X10 | 0X41 1 1 1 1 0
-59.93us | 0X10 | 0X41 1 1 1 1 0
-59.92us | 0X10 | 0X41 1 1 1 1 0
-59.91us | 0XD0 | 0X01 1 1 1 1 0
-59.9us | 0XD0 | 0X41 1 1 1 1 0
-59.89us | 0XFF | 0X41 1 1 1 1 0 VIC prepares to open row ff to
-59.88us | 0XFF | 0X41 1 1 1 1 0 perform an idle fetch at 39ff.
-59.87us | 0XFF | 0X41 1 1 1 1 0
-59.86us | 0XFF | 0X41 1 1 1 1 0
-59.85us | 0XFF | 0X41 1 1 1 1 0
-59.84us | 0XFF | 0X41 1 1 1 1 0
-59.83us | 0XFF | 0X41 1 1 1 1 0
-59.82us | 0XFF | 0X41 1 1 1 1 0
-59.81us | 0XFF | 0X41 1 1 1 0 0 Badline detected! BA pulled low.
-59.8us | 0XD7 | 0X41 1 0 1 0 0 RAS pulled while address lines
-59.79us | 0XC7 | 0X41 1 0 1 0 0 transition from ff to 00.
-59.78us | 0X07 | 0X41 1 0 1 0 0
-59.77us | 0X00 | 0X41 1 0 1 0 0
-59.76us | 0X00 | 0X41 1 0 1 0 0
-59.75us | 0X38 | 0X41 1 0 1 0 0
-59.74us | 0X78 | 0X41 1 0 1 0 0
-59.73us | 0X78 | 0X41 1 0 1 0 0
-59.72us | 0X78 | 0X41 1 0 1 0 0
-59.71us | 0X78 | 0X41 1 0 1 0 0
-59.7us | 0X38 | 0X41 1 0 1 0 0
-59.69us | 0X38 | 0X41 1 0 0 0 0 It seems that VIC suddenly decided
-59.68us | 0X38 | 0X41 1 0 0 0 0 to read from 3800 instead.
-59.67us | 0X38 | 0X41 1 0 0 0 0
-59.66us | 0X38 | 0X00 1 0 0 0 0
-59.65us | 0X38 | 0X00 1 0 0 0 0 Data at 3800 is 00.
What happens is that VIC is about to do an idle fetch, but suddenly decides to
read from another address instead. This causes RAS to transition to a low level
while the address lines are unstable, so the row multiplexer inside the DRAM
enters a metastable state. This means that it will flicker rapidly between
several rows, connecting and disconnecting them from the column lines. Every
involved row will bleed out some (or all) of its charge, and the column lines
end up containing a mixture of the bits involved. Eventually, the row
multiplexer probably decides on one of the rows, and this one will get
refreshed (with the garbage on the column lines) when RAS is released. The
other rows may or may not have been corrupted in the process.
I can think of two ways forward now. One is to try to come up with a hardware
fix. For instance, it seems that RAS is always pulled low at a certain time
with respect to the current halfcycle. Could we perhaps move it a bit earlier
during each VIC halfcycle? (Note: This might cause problems if the address
lines are changed later under some circumstances, so it calls for extensive
testing.)
The other approach is more software based. Where does the address 3800 come
from? Can we manipulate the VIC state somehow to cause it to read other
addresses here? The other two flibug fetches read from 11ff (as would be
expected from the graphics mode used when the trace was taken). The goal would
be to figure out a way to always make this address have an LSB that matches the
LSB of what VIC would have fetched in that halfcycle if the badline weren't
triggered (which would be ff during refresh and idle mode). That way, no
address lines would change during the RAS strobe, and the metastability would
be avoided. It remains to see if it's possible to achieve a stable VSP this
way, and existing demos would still crash, of course.
Finally, a remark on the phenomenon where a crash prone machine can sometimes
power on in a stable mode. This is a complete shot in the dark, but here's my
guess: The system clock oscillator starts at a random phase with respect to the
power supply ripple. Since there is an integer number of clock cycles per 50 Hz
frame, this phase remains constant (or drifts slowly, depending on the accuracy
of the crystal) once the machine is running. Since the supply voltage affects
the fall and (particularly) rise times of the signals in the c64, the timing
around the critical RAS strobe moment would be slightly different depending on
this phase relationship, and thus affect whether metastability occurs. This
also fits with the observation that better power supplies (with less ripple)
remove the bug in some cases.
|
| |
Frantic
Registered: Mar 2003
Posts: 1627 |
I've said it before, but now I have to say it again: I love this thread! lft may definitely be onto something! |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
The frequency of PAL C64 is 50.12 Hz and thus it should quickly desync compared to the (expected) 50 Hz supply voltage.
Another little-known fact about the VIC that *might* contribute in some cases:
The VIC uses a shift register for adressing its 40 12-bit buffer cells that are fetched during bad lines. At the start of a non-idle line (wherever it starts - i.e. at row start or later in case of VSP) a set bit gets shifted in and is shifted by 1 step in every cycle (also during idle lines and in sideborders).
However, when the VSP occurs near the right edge there's still a set bit in the shift register left from previous line when the next line starts, leading to 2 set bits at once.
What happens now depends on circumstances:
* When the next line is an idle line (possible on C128 via $D030 tricks), it won't shift in another set bit at line start (since it's idle), but since there's still a bit set in idle mode it'll apply buffer contents to the idle pattern.
* When this next line is a bad line, it'll have 2 set bits at once and thus write to 2 buffers near the left edge but correct that by overwriting just the right-edge part near the right edge.
* When the next line is a non-bad line (the default), strange things happen. When the VIC reads from both buffer cells at once it mangles both contents more or less. It's AND most of the time but it varies a lot, depending on buffer cell, time (= flickering in some cells), temperature (when the VIC heats up the flickering changes noticeably), model (C128 just ANDs much more often than C64) and individual VIC. And interestingly the result of that is written back into both cells so the bug is also apparent in further lines of the same char row.
This circuity is atypical - instead of the usual NMOS logic stuff (1 by default, 0 wins in case of multiple conflicting writes) this is 0 by default (idle) and in case of conflicts sometimes 0 wins but most of the time 1.
Maybe this causes more power than usual to be drained.
[Edit: clarified a bit]
Something different: someone claimed that VSP crashes are due to refresh being messed up. But that doesn't sound that logical to me. The VIC refreshes the same memory cell every 3.3 milliseconds, so even when disturbed a few times per frame the refresh cycles should still be well within limits of the RAMs being used. What lft wrote above makes much more sense IMO. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
I hadn't even realised earlier that the address lines weren't stable at that moment!
All I paid attention at was how there was ALWAYS a badline just before the memory got trashed.
|
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
There's a mistake in my previous post: I meant "and in case of conflicts sometimes 1 wins but most of the time 0" and not the other way round as I accidentally wrote. |
| |
lft
Registered: Jul 2007
Posts: 369 |
We don't know yet whether the VIC always switches from the expected bitmap fetch to some dummy address that ends with $00. Hopefully Zer0-X will provide more data to back it up. But *IF* that is true, then here's a suggestion for a stable VSP routine:
At cycle 54..57 of line $30, create a badline condition (as if you wanted to redraw the last character row of the previous frame). Also make sure to select a character based graphics mode. Furthermore, on the character line in the VIC line buffer (e.g. the last character line from the previous frame), make sure that every character code ends with 5 zero bits. This way, at line $31 RC will be zero, and if we don't do anything, VIC will fetch bitmap data from font locations that end with $00. But if we do VSP somewhere on line $31 (possibly selecting a bitmap mode at the same time), the address lines will already be $00 when VIC changes its mind and tries to read from the dummy address. Hence, there won't be a metastability hazard anymore.
Anyway, I'm just jotting this down quickly before lunch in a feeble attempt to get it off my mind, and I haven't tried it (I don't even have a VSP crashing machine). If you want to be the first to code a stable VSP, here's your opportunity. =) If it doesn't work, this still tells us that the dummy address may not predictably end in $00, which is useful information for further research. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Addendum: Of course, you have to do this on every frame. So you have to somehow fill the VIC line buffer with safe character codes at the end of each frame. I suggest you use a spare video matrix filled with zero bytes or something, and switch to it before the last badline. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
@lft: that won't work, unfortunately.
VSP only works by leaving _idle mode_ in the middle of a line by causing a bad line condition because the VIC doesn't increment its character pointer in idle mode so it ends up having it incremented by less than 40 chars at the end of the line.
It won't work if the line starts non-bad non-idle because also in that mode the character pointer is incremented so by the end of the line the VIC has incremented it by the usual 40 chars.
What your suggestion does: it causes a character row starting at line $31 but without a bad line. So it'll re-use the characters and colors still in its buffers from the last row of the previous frame. Activating a bad line condition in the middle of row $31 now just makes the VIC fetch the remainder of the first row (after 3 "FLI bug" chars of course).
Edit:
It looks like it's impossible to secure VSP. The low address byte of idle fetch is always $FF but the low address byte of a normal fetch won't ever reach that value - unless of course you've used VSP before on the same frame :D |
| |
DeeKay
Registered: Nov 2002
Posts: 362 |
This being-inbetween-states thingy kinda reminds me of what Jens and Ninja found out when they investigated the bug that the MMC Replay would not load properly and crash when some sprite (I think it was Sprite 6) was turned on. Maybe they can share what they found out when measuring the address lines on the expansion port? ;-) |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
I looked through everything again. My "impossible" line conclusion from my previous post was wrong, but it still seems to be impossible to fix.
First of all, I guess the VIC is going to fetch from $3807 (and not from $3800) in above dump. That would make sense as the character line is 7 and there's even a $07 flashing briefly.
But the upper 5 bits must all be set to 1 as well for a fix to work.
Character mode won't work - the VIC is doing an idle access that cycle and thus character data is 0, meaning that those 5 bits would be 0 as well.
Bitmap mode won't work either - without VSP the VIC can only do 320-byte increments, meaning that the only values to choose from for this lowmost byte would be $07, $47, $87 and $C7. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting KabutoVSP only works by leaving _idle mode_ in the middle of a line
Doh! You're quite right. Sorry for getting everybody's hopes up.
The dummy address (3800 or maybe 3807 as you point out) doesn't seem to be what VIC would have fetched if this were a normal display line (that would've been too easy). In the captured crash, d018 had not been modified and ECM was active, so VIC would've fetched font bits from 1000-11ff. That's why we need more data, to see if the dummy address is a constant or if it can somehow be manipulated.
But I agree that the least significant bits may reflect the value of RC. If so, this leads us to another workaround, but this is not practical at all: Basically, it would mean that when you perform VSP, all memory locations that end with 7 or f may get trashed. So avoid them! For code, you could use e.g. 2-byte nops to skip them. After doing VSP, you could restore some of these bytes (the interrupt vector at $ffff, for instance). You could store the next part (or loader) split into 7-byte chunks, and use a small 7/f-avoiding routine to unpack them. Very tricky, but that's what we do.
But like I said, this is not practical. Even if you decide to allow graphics to get corrupted as long as the code doesn't crash, you still have to deal with the music routine. With an 8 KB tune, that's 1 KB of potential code you have to restore every frame (and if you use an unrolled loop, that loop would also have to be 7/f-avoiding); but the point of VSP in the first place was to avoid shuffling a lot of data.
We're back to the crossroads of my first post in this thread: Hardware fix (which should be quite easy using a 555 or something: pull down RAS a fixed amount of time after PH0 goes high, then release it immediately when PH0 goes low), and/or figure out if it's possible to change the dummy address. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting KabutoBitmap mode won't work either - without VSP the VIC can only do 320-byte increments, meaning that the only values to choose from for this lowmost byte would be $07, $47, $87 and $C7.
$c7 would be better than $07. In this case, only memory locations ending in c7, cf, d7, df, e7, ef, f7 and ff would get trashed. Hence, a large chunk of each page would be safe for code.
But this is based on a number of assumptions: That the dummy address contains some bits of VC during bitmap modes, that the row multiplexer only flickers between the rows whose addresses match the pattern on the address bus, and so on. After all, we only have one crash log from one machine. I'm looking forward to a larger data set! |
| |
lft
Registered: Jul 2007
Posts: 369 |
Alas, the address won't end in c7. VC will end in c0, but VC is shifted by three when forming the address. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
I disagree. VC address always increments by 40, no matter what gfx mode is used, unless you use VSP. I already accounted for the shift-by-3 in bitmap mode by writing about "320-byte increments". So e.g. after 3 rows VC address is $78, shifting by 3 -> $3C0, adding 7 (for row 7) -> $3C7, taking just the lowmost byte -> $C7.
EDIT: Fun fact: My C128DCR seems to behave differently. It doesn't display the idle byte for the fetch in question, it either fetches another byte (in default charset mode that might be line 7 of char 0 (@) which has byte value 0) or doesn't display anything at all. |
| |
DeeKay
Registered: Nov 2002
Posts: 362 |
So is the theory on what's actually happening confirmed now? Cause if it is, we can go the next step and ask ourselves what exactly the hardware difference between the machines suffering from VSP-problems and those that do not is! ;-) AND why some machines only seem to suffer temporarily from it, at least according to folklore i heard ("when it's on for a few minutes the problems go away") |
| |
DeeKay
Registered: Nov 2002
Posts: 362 |
Quote: I disagree. VC address always increments by 40, no matter what gfx mode is used, unless you use VSP. I already accounted for the shift-by-3 in bitmap mode by writing about "320-byte increments". So e.g. after 3 rows VC address is $78, shifting by 3 -> $3C0, adding 7 (for row 7) -> $3C7, taking just the lowmost byte -> $C7.
EDIT: Fun fact: My C128DCR seems to behave differently. It doesn't display the idle byte for the fetch in question, it either fetches another byte (in default charset mode that might be line 7 of char 0 (@) which has byte value 0) or doesn't display anything at all.
Interesting. Cause line 6 of the @ contains the only bit of the ROMchar that is NOT a straight EOR#$FF of the inverted character, as all people who accessed the NUFLI editor hidden part in Leon's picture can confirm! ;-) COINCIDENCE??? |
| |
Skate
Registered: Jul 2003
Posts: 491 |
Don't we have a contact with any ex-Commodore engineers? If i were one of them and someone asked me a question like VSP bug, I'd be interested in finding the cause of the problem. I'm not saying they would be interested or they could help but why not inviting them to this discussion?
Since I don't know any of the ex-Commodore company guys, i just wanted to ask if any of you know them. I believe some of you should have contact addresses from a magazine interview etc. right? |
| |
DeeKay
Registered: Nov 2002
Posts: 362 |
Skate: Even if they could offer up an explanation on why this is happening (remember: a lot of the VIC behaviour we know and exploit today are ill side effects that were never consciously planned for), do you really think they could provide insight into RAS timings some 25 years later? <:-) |
| |
Skate
Registered: Jul 2003
Posts: 491 |
@DeeKay: Even if they have nothing to contribute (actually i doubt that), i'd like them to see and join this discussion. |
| |
enthusi
Registered: May 2004
Posts: 675 |
Personally, I think VSP-fx should be depreciated for that very reason. And yes, I know that's alot to ask.
But I think that's what kept the c64-scene that vivid.
Now, with it becoming more and more of an emulator scene (much less so than any other oldschool systems though to my knowledge) VSP crashes may become less and less relevant but I think its an important principle to at least remember this.
Same goes for grey dots, samples on new sid, audio-screen-sync timed to emulator-delays etc.
|
| |
DeeKay
Registered: Nov 2002
Posts: 362 |
n2c: that's really too much to ask! <:-) I for one wouldn't wanna miss Dutch Breeze 's diagonal scrolling logo or amazing dragon-intro, Gotcha's awesome AGSP-gfx in That's Design , Thomas Heinrich's amazing GFX in Another World , Mayhem in Monsterland and countless amazing bitmap scrolling fonts for anything in the world!
It's the only known way to actually scroll bitmap further than 7 pixels, that's why VSP has been used extensively throughout the c64's software catalogue ever since it was discovered (somewhen in the late 80s IIRC), and asking people NOW to stop using it is like asking them to stop using sprites!...
No, we must come up with a hardware fix - and if we can't, well, it'll just have to go on like it did before... which wasn't really THAT annoying, tbh I never had a single machine where VSPs crashed! <:-) And I've owned a few!... |
| |
encore
Registered: Aug 2010
Posts: 61 |
Quoting SkateDon't we have a contact with any ex-Commodore engineers? If i were one of them and someone asked me a question like VSP bug, I'd be interested in finding the cause of the problem. I'm not saying they would be interested or they could help but why not inviting them to this discussion?
I agree and wrote a suggestion in the start of this thread:
Quoting encoreHow about asking Bil Herd? After seeing a couple of his videos, I could imagine that he would have an idea or two.
http://c128.com/forums/general-discussion
|
| |
Skate
Registered: Jul 2003
Posts: 491 |
@encore: i wish i knew who Bil Herd was. :))) so, anyone contacted or planning to contact him?
edit: i sent a message to Jeri Ellsworth to join and/or invite Bil Herd and others to this discussion. i just remembered even if i don't have a contact with the guys, i have a contact with someone who has a contact with them. :) |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
I'm not enough of a hardware guru to understand all the intricacies of this discussion, but at least it seems to me that the hardware "bug" is confirmed, and it would be good if it would convince people to stop using the god damn VSP effects!
I got a bit annoyed when I sat down to watch the x2012 demos and had to resort to an emulator to watch Trick and treat because it crashed on the VSP effect on the first disc.
I don't see why there is such a large acceptance of VSP when it is not working properly for a large percentage of the hardware. It would be like releasing a demo with an IRQ loader that only runs on 1541-II (and not 1541-I, oceanic, 1541U etc.) or something. Sure it works for those that have that hardware, and you can tell those that don't to "just buy one", but people would rightfully think that your code is a bit crappy.
|
| |
ready.
Registered: Feb 2003
Posts: 441 |
Or forsee a way to skipp the VSP part so the demo can continue. This is the best compromise in my opinion. Without VSP lots of nice effects would be trashed, but adding a way to keep compatibility is also nice. |
| |
Oswald
Registered: Apr 2002
Posts: 5022 |
 http://www.quickmeme.com/meme/3rp4cj http://www.quickmeme.com/meme/3rp4cj
VSP is accepted since before dutch breeze or so, and it is even more so since emulators, get a machine which can handle it. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11127 |
Quote:I don't see why there is such a large acceptance of VSP when it is not working properly for a large percentage of the hardware. It would be like releasing a demo with an IRQ loader that only runs on 1541-II (and not 1541-I, oceanic, 1541U etc.) or something. Sure it works for those that have that hardware, and you can tell those that don't to "just buy one", but people would rightfully think that your code is a bit crappy.
don't ever diss dutch breeze, lamer.
=P |
| |
lft
Registered: Jul 2007
Posts: 369 |
Remember that the VSP crash could occur even when we don't deliberately try to use VSP. For instance, consider a very simple up-scrolling game that does everything by the book and doesn't even have a raster interrupt. It would still have to change YSCROLL from 3 to 0 during initialisation, and if this happens during the visible portion of rasterline $30 (and there's a 0.2% probability of this), it could trigger a VSP crash. So it is a real bug (in the sense that specifications are violated) that some machines have. Do we fix those machines or do we avoid changing YSCROLL? |
| |
raven
Account closed
Registered: Jan 2002
Posts: 137 |
Shadow: You'll be surprised how many demos don't work on my 128D due to loaders that don't like the 1571 drive.
A few recent examples are "Trick and Treat" and "Edge of Disgrace".
With other demos there are random crashes after file loading ("Artphosis" and "Vicious SID 2" are such examples).
As for VSP, since the 80's I owned or had access to over 50 different C64 and C128/D machines.
I still haven't found a machine that would crash with VSP and I tried really hard to find one back when testing "Insomnia", which uses VSP quite heavily.
My only assumption is that these machines are rare, which is why I don't think VSP should be "banned" :)
I agree with Oswald, get a machine that can handle it ;) |
| |
Oswald
Registered: Apr 2002
Posts: 5022 |
"I still haven't found a machine that would crash with VSP "
maybe try older ones. back in the days I had an old sid machine which couldnt handle it at all.
btw, another funny thing happened once at one of my friend, the machine did not erase its ram on a power cycle. some game screen came back over and over again (more and more trashed), while we tried to get the basic prompt by power cycling :) |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
No fucking way - I've had my C64C for 24 years now and it will remain my main machine forever! :P
I actually bought an old breadbox C64 just to be able to watch demos using VSP-crap but it just didn't feel right somehow, graphics output not as crisp, sound not as good.
|
| |
chatGPZ
Registered: Dec 2001
Posts: 11127 |
that often happens with certain batches of machines that have chinese ram chips (which hold their data for literally seconds without power) |
| |
Danzig
Registered: Jun 2002
Posts: 429 |
Quote: "I still haven't found a machine that would crash with VSP "
maybe try older ones. back in the days I had an old sid machine which couldnt handle it at all.
btw, another funny thing happened once at one of my friend, the machine did not erase its ram on a power cycle. some game screen came back over and over again (more and more trashed), while we tried to get the basic prompt by power cycling :)
I got such a machine, too, (my first C64 (C64C)) and I could switch it off, wait 2 minutes, switch it on and still start V3-Turbo with Sys. BUT that machine suffered from VSP-bug IMMEDIATELY! I have seen lots of demoparts years later on other peoples machine :/ The mentioned "feature" was the fact that I never believed the "ram-refresh is fuxxored"-explanation about VSP. In my head there is still the simple rule of thumb: "Breadcase=VSP works - Any other case including C128=VSP crashes" I never ever had a Breadbox that crashed on VSP. |
| |
raven
Account closed
Registered: Jan 2002
Posts: 137 |
Oswald: most of my C64's are the old type (breadbox), only have a few C64C. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
I just had to try it. I put 8565R2 into a breadbox and couldn't get that to crash. I also put 6569R3 into the new board (running from SIDs 9 volts just fine) and so far haven't been able to crash that one either. |
| |
encore
Registered: Aug 2010
Posts: 61 |
Quoting Skate@encore: i wish i knew who Bil Herd was. :))) http://en.wikipedia.org/wiki/Bil_Herd |
| |
Oswald
Registered: Apr 2002
Posts: 5022 |
uhh, Bil Herd is one of the greatest C= engineers, designed single handedly the TED machines, c128, and more. read "on the edge" its a must :) |
| |
AmiDog
Registered: Mar 2003
Posts: 97 |
Perhaps a stupid question, but as the VSP crashes seems to be RAM related, what would happend if one replaced the DRAM with some SRAM instead (assuming it's technically possible)? |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Quote: Perhaps a stupid question, but as the VSP crashes seems to be RAM related, what would happend if one replaced the DRAM with some SRAM instead (assuming it's technically possible)?
Several people have been suggesting already long ago that SRAMs would prevent the crash since they wouldn't suffer from glitches during refresh cycles. It would require some extra logic tho.
Regarding that old VIC running on the new board, it had crashed while running Royal Arte last night. It also has been running Tequila Sunrise for almost 10 hours today without problems. Tho it could all be due to powercycling inbetween as it has an effect to the internal timings of the VIC, more in 8565 than in 6569. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
Idea: the DRAM batch might play a role, too. DRAMs buffer the address applied during RAS resp. CAS internally. Susceptibility for messing up might depend on internal logics of the DRAM in question.
I suppose Commodore put the cheapest RAM they could get, even mixing multiple batches for single units. (I have a C64 which had bad RAM chips - so bad that it booted with ?OUT OF MEMORY ERROR. All 8 RAM chips had the same label, just 4 had a shiny case and 4 had a mat case. 3 of the shiny ones were clearly defective so I replaced all 4.)
So there should be a lot of different RAM batches in all the C64s that were ever built. Unfortunately RAMs aren't socketed and thus require desoldering for replacement. But it might be worth a try on a machine that crashes.
Would it be worth collecting info about C64s (such as RAM labels) that do crash to track down the problem? What do you think? |
| |
lft
Registered: Jul 2007
Posts: 369 |
All right folks. Zer0-X and I stumbled over something interesting.
Remember that the VSP crash is caused by a metastability hazard, whereby VIC changes its mind about what address to read at the exact moment when the row address is latched into the DRAM chips. (This hazard leads to a crash with some probability, and the probability seems to be different depending on machine, temperature, phase of moon and so on.)
We have discovered that, at least for some machines, the timing is different depending on how you trigger the VSP effect. As mentioned in the VIC article, VSP (DMA delay) can be triggered in two different ways on rasterline $30: Either by changing YSCROLL to 0 or by changing the DEN bit to 1. It would appear that VIC changes its mind about the address slightly later if you use the DEN method -- and by that time, the row address has already been latched safely.
This seems too simple to be true, so we need independent verification. We are asking you to test the attached program on your crash prone machines, and see if it crashes. We would also like you to test it on your stable machines, to see if the changed timing perhaps causes crashes where there previously weren't any. (If so, this could be tested at runtime and the VSP code modified accordingly.)
Here is the program: http://www.linusakesson.net/files/dentest.prg
I would also like to thank SounDemoN for helping us out with additional testing. |
| |
Stone
Registered: Oct 2006
Posts: 168 |
Extremely interesting thread! I just thought I'd add some of my own experience on the subject and let you guys decide its relevance. I have an old breadbin (early eighties) that has excibited a degradation in stability, not only with vsp, but also other $d011 related splits. The timeline of when the crashes started occuring goes something like this: (late 80s) VSP -> Illegal modes (bitmap+egbm) -> bitmap+fld -> simple bitmap splits (90s). How accurate this timeline is, I don't really know..
With my extremely limited knowledge of electronics, this would suggest to me that the degradation I have seen is caused by leaky capacitors and that there at least can be a hardware solution to this (as already suggested). |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
@Stein: Did you try using a different power supply? Or measuring the supply voltage at the VIC while the machine is running? (Depending on your knowledge of electronics you might have someone else do that for you so you don't accidentally short circuit anything)
@lft: This would indeed fix the problem but if I didn't get anything wrong there's a disadvantage: it reduces usable screen resolution for combined VSP+linecrunch (to scroll the bitmap wherever you want) in most cases.
When doing linecrunch first it can start right at row $30 (for 25 lines), be directly followed by VSP, and directly after the VSP row it's possible to cause a bad line for image display.
However, the DEN method forces one to use VSP first. The VSP line is always followed by 8 non-idle displayed raster lines (except for C128 where it's possible to use $D030 to work around) but linecrunch only works for lines that would normally be idle. Thus you'd have the VSP line, then 8 wasted lines, then 24 or 25 linecrunch lines.
|
| |
encore
Registered: Aug 2010
Posts: 61 |
lft: For what it's worth, my VSP-stable Hong Kong manufactured C64C (with old SID) has been running dentest.prg for more than 1 hour without any problems. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
@lft: Your code changes $D011 from $08 to $18. Did you try changing the line as well (e.g. changing $D011 from $07 to $18)? I don't think there'll be a large difference but it might affect timing a bit as well.
Or generally: does the actual line change for VSP cause timing differences? I.e. changing $D011 from $18 to $17 resp. $17 to $18? Since it's NMOS it might create a small timing difference, too. |
| |
Stone
Registered: Oct 2006
Posts: 168 |
@Kabuto: I never tried it with another powersupply. The old one went up in smoke a couple of years ago, so if I ever get the machine out of the basement again, I'll test it with a new one. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting KabutoHowever, the DEN method forces one to use VSP first. The VSP line is always followed by 8 non-idle displayed raster lines (except for C128 where it's possible to use $D030 to work around) but linecrunch only works for lines that would normally be idle. Thus you'd have the VSP line, then 8 wasted lines, then 24 or 25 linecrunch lines.
EDIT: Removed faulty reasoning that was off by a cycle. You were right.
Quoting KabutoOr generally: does the actual line change for VSP cause timing differences? I.e. changing $D011 from $18 to $17 resp. $17 to $18? Since it's NMOS it might create a small timing difference, too.
Good idea! We'll have to measure that. |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
lft: dentest.prg is shaking along nicely on my crash-prone C64.
Could you perhaps produce a similar program but with the "old" method, just to have as a reference and see if that crashes? |
| |
Mace
Registered: May 2002
Posts: 1799 |
I ran the test program in Vice on all my PCs, none crashed.
(Sorry, couldn't resist ;-) )
Plus Shadow's request to have a program do both methods. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Here's a version using YSCROLL instead of DEN, everything else being identical. This one should crash.
http://www.linusakesson.net/files/dentest3.prg
If the horizontal shaking stops, that's a crash. Or if the border turns red, or if there's garbage on the screen etc. |
| |
6R6
Registered: Feb 2002
Posts: 244 |
And I ran the DEN test program on my C64c that normally crashes instantly with vsp's. Had it running for 10-15 mins - No crash. |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
No conclusive results from me yet, it seems like my C64 had a "good" day today, because the dentest3.prg didn't crash it either.
Will rerun the tests once the machine has had time to cool down... |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
@lft: Your dentest3.prg triggers VSP using both YScroll and DEN at once ($17 -> $18). Intentionally?
Here are 2 further test progs:
http://kabuto.untergrund.net/files/c64stuff/dentest3a.prg - like lft's dentest3.prg, but this sets just YScroll ($1F -> $18)
http://kabuto.untergrund.net/files/c64stuff/dentest3b.prg - like dentest3a.prg, but the other way round ($18 -> $1F) |
| |
lft
Registered: Jul 2007
Posts: 369 |
@Kabuto: That's unintentional, but it's the 25-row bit, not DEN, so it shouldn't affect things.
By the way, we also measured going from zeroes to ones in YSCROLL ($18 -> $19 on line $31 to be precise), and there is a slight change in timing. However, it's in the wrong direction, making the address lines change earlier and still interfere with RAS. |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
Alright, today my C64 was in a VSP-crash-prone mood. dentest3.prg (and dentest3a.prg for that matter) crashed within seconds, but dentest.prg seemed stable.
Maybe lft is onto something here? Would be very nice if there was an all-model-compatible way to do VSP! |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Tested dentest and dentest3 with a weak psu (from 1990) and no cart without a crash on these machines:
Light color, slim case, 6581 (C64C, ser.no.: DA4082521B, made in W.Germany)
Light color case, dark keys, breadbox form, 6581 (C64, ser.no.: UKB2257171, made in the UK)
Light color, slim case, 8580 (C64E, ser.no.: 665338, made in W.Germany)
...I will go on with testing with a converted AT-PSU (http://c64.rulez.org/capac/CapaC_Weblapja/C64%20hardver%20dac.h..) and other machines... |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Light color, slim case, 8580 (C64E, ser.no.: HB4859600E, made in Hong Kong) no crash... |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Light color, slim case, 8580 (C64E, ser.no.: HB4 045509E, made in China)... no crash. (done using a modified AT-PSU) |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Light color, slim case, 8580 (C64E, ser.no.: HB4 1499711E, made in Hong Kong)... dentest crashed 2 times, dentest3 didn't (done using a modified AT-PSU) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting PoisonLight color, slim case, 8580 (C64E, ser.no.: HB4 1499711E, made in Hong Kong)... dentest crashed 2 times, dentest3 didn't (done using a modified AT-PSU)
Meh, how annoying. I appreciate that you tested and reported it, though!
It is still possible that the timing difference ensures that only one of the methods (DEN or YSCROLL) can crash on a given machine. For approximately how long did you run dentest3? |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Quote: Quoting PoisonLight color, slim case, 8580 (C64E, ser.no.: HB4 1499711E, made in Hong Kong)... dentest crashed 2 times, dentest3 didn't (done using a modified AT-PSU)
Meh, how annoying. I appreciate that you tested and reported it, though!
It is still possible that the timing difference ensures that only one of the methods (DEN or YSCROLL) can crash on a given machine. For approximately how long did you run dentest3?
10-15 minutes each. Should I redo the test with this machine? |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting Poison10-15 minutes each. Should I redo the test with this machine?
Yes please. Especially dentest3.prg, to find out if it's possible that both methods can crash on the same machine. If not, then future demos could have an option for which VSP method to use.
It would be really nice to also get a signal trace from that machine, to see how the phi clock, RAS, BA and the address lines change when VSP is triggered using each of the two methods. But I don't suppose you have such equipment..? |
| |
Poison
Registered: Oct 2004
Posts: 7 |
Same machine, 2 times 30min test (dentest / dentest3), no crash... |
| |
soci
Registered: Sep 2003
Posts: 474 |
C128DCR crashed here with the dentest method after some time (1 hour?). Corrupted addresses seem to be xx97.
A bit disappointing, I still had some hope even if Poison told it crashed for him.
I've spent quite some time moving up 6 pixels a heavy irq/nmi based multiplexing code with sprites moving over the VSP area on open top/bottom borders just to make sure that the VSP can be triggered at line $30 with $10 toggling.
Now I know I don't have to figure out the remaining bugs and can go back to the previous working version ;)
Any more ideas how to get a stable VSP? I also have my soldering iron ready ;)
|
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
Now that lft spent some effort working around every 8th byte being prone to corruption let's continue the discussion, maybe things can be improved further :-)
1. The idle byte just before the "VSP bug" is a usual idle byte on all C64s while my C128DCR fetches a different byte (likely line 7 of the @) but besides that runs stable as well. So the C64s are too slow and the C128DCR is too fast to trigger the bug. Could there be a kind of "sweet spot" in terms of production dates?
2. Linecrunching 3 rasterlines before VSP and using bitmap mode during VSP should use low byte $C7 instead of $07. Less bytes to get corrupted but also a bit less usable screen height and (relevant for pure VSP) sprite bug occurring earlier.
3. Does the memory corruption have any predictable pattern? I.e. when 2 columns get mingled what's the outcome depending on the input? Is it predictable (i.e. always ANDed or ORed)? (In this case one could set up 2 test tables, one containing $FF / $00 for even / odd bit weight (= number of set bits within the low address byte) and the other one being inverted and do a quick test to determine which columns were actually corrupted). Or is the outcome at least the same for both mingled columns? (Edit: just 1 or 4 bits might get corrupted at once so watch out when testing that) |
| |
Burglar
Registered: Dec 2004
Posts: 1033 |
I think you should start a new thread with "VSP crash (solved)" or something ;)
discussing ways to simplify and improve on lft's fab work should be interesting! |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting Kabuto2. Linecrunching 3 rasterlines before VSP and using bitmap mode during VSP should use low byte $C7 instead of $07. Less bytes to get corrupted but also a bit less usable screen height and (relevant for pure VSP) sprite bug occurring earlier.
I actually tried that, but when I finally got hold of a crash-prone machine that effect crashed instantly. I conclude that for some reason the bus lines do not change to the expected display-mode lsb, at least not immediately.
However, it appears that my demo doesn't crash (trigger the cross-refresh behaviour) on some machines that usually crash on VSP effects. This suggests that it is possible, somehow, to affect either the lsb or the timing from software. Probably the latter. If it turns out to be possible to adjust the timing, I don't think we will find a setting that is safe on all machines, though. But there is certainly more to find out.
What is the sprite bug you refer to? |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
It's the sprite pointer area. "Sprite bug" might not be a good term but it's kind of a bug that needs to be worked around if you want to use AGSP + sprites at once. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Just in case I better post these old graphs that show one of the problems:
http://oms.wmhost.com/VSP/ |
| |
Burglar
Registered: Dec 2004
Posts: 1033 |
Research must continue of course, but wouldn't it be nice to create more safe vsp code. I mean, as far as we know lft's method works, but it's quite complicated.
Take the double screen compo for example, wouldn't it be cool if we could supply source code of a safe vsp displayer. Hopefully it would also help to get more testers. |
| |
Zer0-X
Registered: Aug 2008
Posts: 78 |
Theorize this.
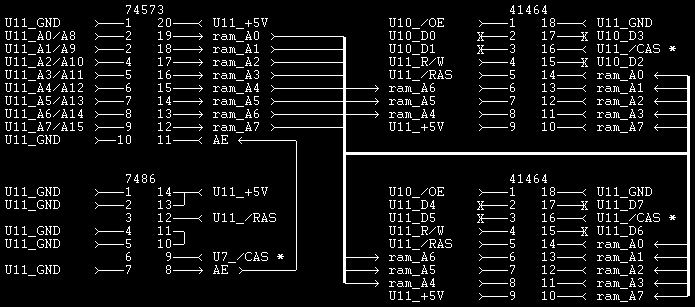
Shhit... Fixed the labeling of 7486 (was erraneously 7408). |
| |
chatGPZ
Registered: Dec 2001
Posts: 11127 |
Quote:wouldn't it be cool if we could supply source code of a safe vsp displayer.
you should try coming up with one... personally i doubt its worth the effort, since you will have to restore the broken graphics all the time, you will certainly see just that. so instead of crashing it would look buggy. i'd just grab another c64 from the pile... :) |
| |
Fungus
Registered: Sep 2002
Posts: 620 |
According to lemming adding buffers to the multiplexers will fix the issue on a breadbox too (he's already done it). Jbevren had the exact same idea after I showed him this schematic yesterday. Preventing VIC from writing to memory at all is the obvious solution then. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11127 |
Quote:Preventing VIC from writing to memory at all is the obvious solution then.
and the ram refresh? :) |
| |
tlr
Registered: Sep 2003
Posts: 1717 |
Quote: Quote:Preventing VIC from writing to memory at all is the obvious solution then.
and the ram refresh? :)
You only need to access each row (RAS) of the memory to make it refresh. No need to write. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11127 |
mmhyes, ok, true =) |
| |
lft
Registered: Jul 2007
Posts: 369 |
I don't know what you're talking about. VIC never writes to RAM. The bit bleeding happens when it tries to open several rows almost at the same time, as I've described previously.
As for latching the bus lines, it's certainly worth a try. But until we have empirical data that supports this method, I'm wary that the unstable bus lines might trigger metastability in the latch chip, causing it to produce unstable output, and we're back to square one. |
